字符集介绍
作者:luomgf
时间:2022/02/16
转载请注明出处:https://www.cnblogs.com/luomgf/p/15904688.html
图文并茂,请访问:http://luomgf.com/16443998998895.html
1、目标
希望你看过后能够明白世间的一切乱码问题,能够明白天下主要字符集的招式讨论. 本次据介绍字符集,我想达到如下的目标,概括来讲就是,写明字符集是怎么产生的,最早的ASCII码是怎么来的,到后面unicode/gb2312/gb18030他们是怎么编码和设计的的,utf8的编码原理,这些字符集的发展伴随了国际那些标准的发布,中国是如何跟进的,发布了那些标准.字符又是怎么被显示出来的,如何显示当今宇宙最复杂的汉字biang.c/python/编程语言和终端是怎么处理字符集问题,字符集怎么转换如何实现等等. 字符集背后隐藏的那些计算机基础知识和发展历史. 欢迎一键三联,支持写下去,当然如若你还有其他想了解的关于字符集的知识趣事可以在评论区留言告诉我,我可以更新进其中.
1.1、字符集
- 字符集的定义
- 常见字符集及登记字符集
- 2.1. ASCII码字符集
- 2.2. 扩展ASCII码字符集
- 2.3. GB2312字符集
- 2.4. GB18030字符集
- 2.5. unicode字符集
- 2.6. utf8存储方式
- 字符集涵盖知识
- 字符编码规则区位/多平面/单字节
- 字符编码存储16进制/ucs2/ucs4
1.2、字形
- 字体矢量/点阵
- 格式truetype/opentype
常见平台软件语言对于字符集的处理
- python语言
- python是怎么支持unicode的,怎么实现utf8和unicode转换
- python是怎么实现各种编码转换的
- c语言怎么处理字符集
- wchar_t是个啥
- linux内核的点阵字体了解吗
1.3、 应用
- 宇宙最复杂汉字怎么在你的电脑上面显示出来
- 宇宙最复杂汉字怎么在你的点阵嵌入式设备上面显示出来
- 文本乱码
- 汉化
- 编码序列化传输
- 网络传输,字符流与字节流
- 终端一般怎么解决字符集,怎么检查乱码,用nc命令模拟,反查
- vim乱码问题怎么处理
1.1、编写python程序库
- 点阵字符程序
- 显示hzk字库点阵字符
- 显示任意字符点阵字符
- 输出任意字符点阵字模
- 创建gb2312/gb18030字符集字库
- 字符集编码程序
- 编码转换,仿照iconv
- 打印某编码特征信息
- gb2312/gb18030 打印区位,国标码
- utf8打印二进制编码
- unicode打印平面
编写c/c++程序
2、字符集
2.1、基本介绍
字符集就是用用一个特定的数字去代表一个字符字形,从而形成的一系列数字构成的数据集合,即为字符集.
《Windows程序设计》1这本书当中,作者基本上介绍了ASCII字符集和UNICODE字符集以及C语言与WINDOWS编程处理字符集问题的技巧,算是比较全的.所以可以推荐读者看看这部分内容.《C Primer Plus》2这本书当中介绍了如何处理宽字符.
ASCII码介绍
标准的ASCII码是一共128个的,由7位编码组成的字符集. 他主要区分的是ANSI标准和iso标准,ANSI标准是美国信息标准,ISO标准是考虑了全球的拉丁文的标准. iso8859-1的的0x00-0x7F就是对应US-ASCII码.
ASCII发展历史时间线和事件
ASCII码定义开始于1963年,最近一次修订是1986年.ASCII的编码字符集思想来源如果要进行追踪,可以追寻到1837年摩尔斯电码,可以说摩尔斯电码是字符集的祖先.
在国外的这篇文章3和维基百科4中,作者列举了ASCII码发布标准的版本,摘录如下:
- ASA X3.4-1963
- ASA X3.4-1965 (approved, but not published, nevertheless used by IBM 2260 & 2265 Display Stations and IBM 2848 Display Control)
- USAS X3.4-1967
- USAS X3.4-1968
- ANSI X3.4-1977
- ANSI X3.4-1986
- ANSI X3.4-1986 (R1992)
- ANSI X3.4-1986 (R1997)
- ANSI INCITS 4-1986 (R2002)
- ANSI INCITS 4-1986 (R2007)
- (ANSI) INCITS 4-1986
- (ANSI) INCITS 4-1986
编码的发展主要故事
上面列举了ASCII码的发展历史时间线,下面对其发展历程中一些主要的事件做一些介绍
- 1838年-1854年,摩尔斯电码,字母用点和横线编码
这是字母编码字形图
 这是从字符自然顺序给的编码表
这是从字符自然顺序给的编码表
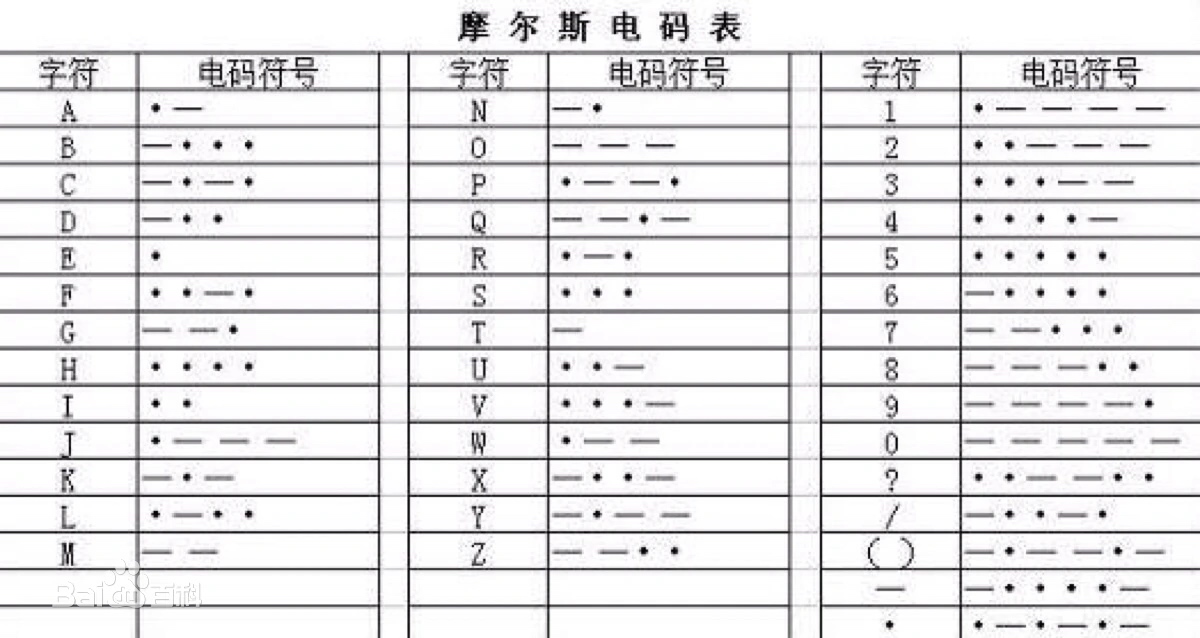
这是从编码设计的角度给出编码规则
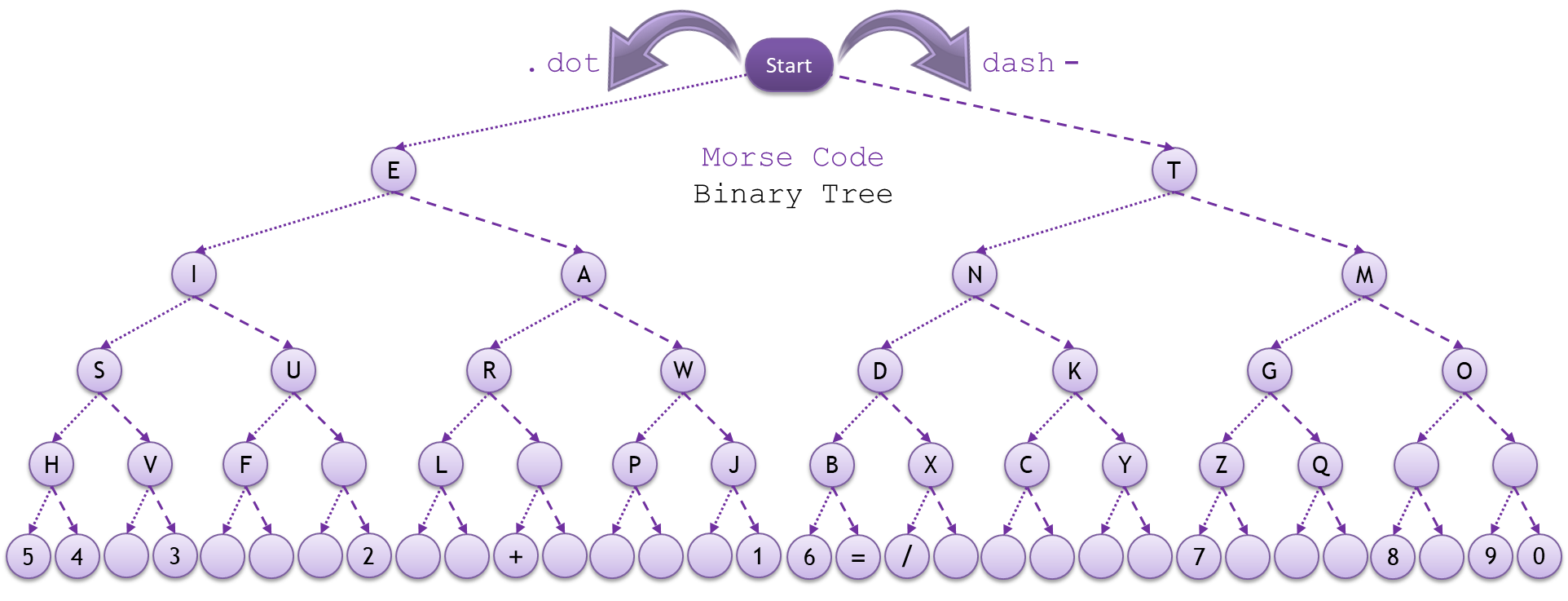
这张图我们仔细观察就会发现其实是一个二叉树,特点:常用字符编码短,每个父节点下的做节点为“.”右节点为“-”,以此类推进行编码.当然这个结论我在书中还没有得到证实,有那部书有这个提法.
作为最早的字符集,在中文里面也有字符集,威基杰的《电报新书》就是最早基于康熙字典的字符集.
电码形成的电文,用的是类似电视上那种滴滴嗒嗒的机器来发射的.

当然我们一些抗战题材中的密码传送也是这个原理,但是他不是用的摩尔斯电码,因为其是明码,谁都能看懂,所以每个军事单位就字节发明字符集,形成电码.然后电视上面抢来抢去的密码本就是字符集.
- 20世纪50年代末,ASCII开始兴起 这个时期编码开始出现雏形,但标准不统一.
- 1963年,第一版ASCII码由美国定义ASA X3.4-1963, 该版ASCII码是第一个由美国国家标准学会定义发布的有记录标准.如下是标准的封面页和设计页,详细内容请看扫描文件5
封面
 设计
设计


-
1967年,定义ASCII码. 在1967年,算是定义了ASCII码,也比较接近现在的ASCII码定义.
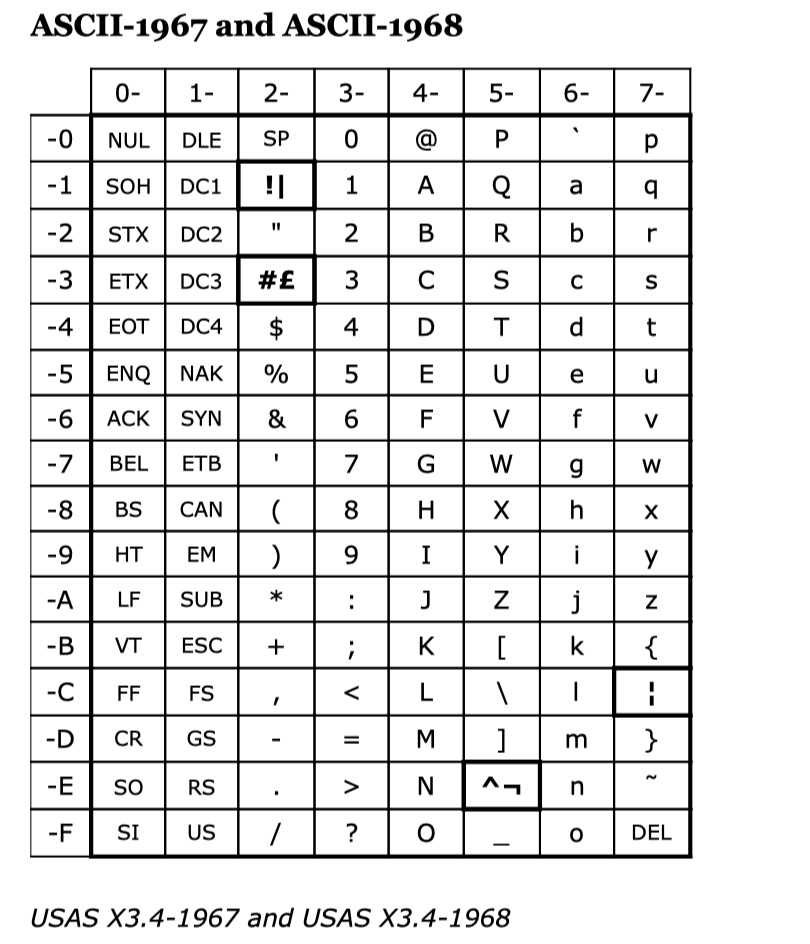
-
1986年,ANSI X3.4-1986 这也是最近一次美国官方ASCII码标准,也叫US- ASCII码.也是和后面国标iso/iec 8859-1一样
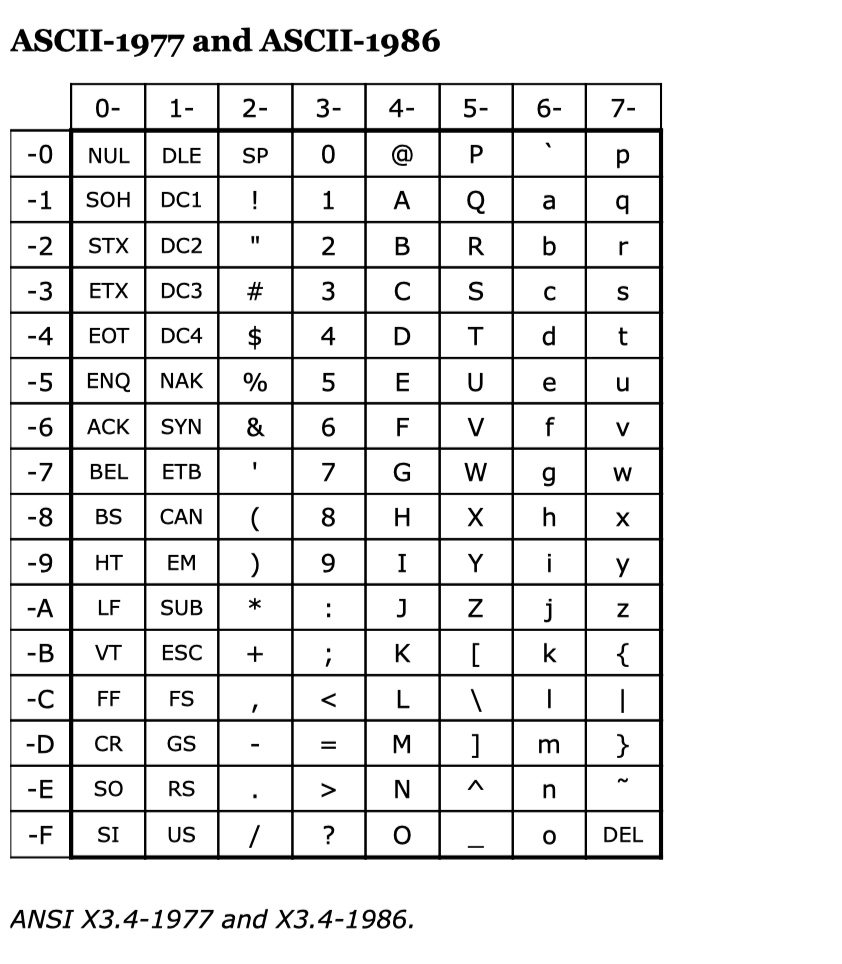
-
1981年,IBM推出8位字节256个字符组成的字符集
由于7位构成的128码位明显不能满足,所以ibm将字符集扩展到了8位,形成256位的字符集.且是第一个有代表性和与硬件密切结合的的字符集,伴随着ibm pc一起出售.
- 1987年,ISO 8859-1——1987,“美国国家信息处理标准——8位字节编码图形字符集——第一部分:拉丁字母第1号”,即“拉丁语-1”
这是第一次iso和iec合并发布8位编码字符集.
- 1991年,ISO/IEC 646:1991,Information technology -- ISO 7-bit coded character set for information interchange
他是 7位编码的最后一个ASCII标准,即替代ISO 646:1983标准.
- 1998年,ISO/IEC 8859-1:1998发布,又称Latin-1或“西欧语言”
这是第二次发布 8位编码的字符集,兼容ASCII码,更新替代:ISO/IEC 8859-1:1987,也是现金大多数软件使用的标准,其别名还有: iso-ir-100, csISOLatin1, latin1, l1, IBM819. Oracle数据库称WE8ISO8859P1的叫法.
相关标准和研究
ASCII码编码概述与内容特点
ASCII码的设计
ASCII码特殊字符背后的故事
扩展ASCII码
ASCII和iso8859的关系
https://www.iso.org/obp/ui/#iso:std:iso-iec:8859:-1:ed-1:v1:en

中国的ASCII标准
GB/T 1988-1998
utf8编码的优势
在《Linux C编程一站式学习》6中,作者演示了直接使用utf8编码,也就是现在我们大家习惯的编辑器设置编码,用c语言处理的优势.因为其编码就是在C语言当中也是可以直接处理的,字符串不用写“L”标志.当然其相应的字符串函数也不能用了.
常见平台软件语言对于字符集的处理
python语言
- python是怎么支持unicode的,怎么实现utf8和unicode转换
- python是怎么实现各种编码转换的
c语言怎么处理字符集
- wchar_t是个啥 ANSI/ISO 9899——1990,ANSI C
- linux内核的点阵字体了解吗
git log ./lib/fonts/font_8x16.c
git log -- drivers/video/console/font_8x16.c
标准
标准清单
标准引用发展关系
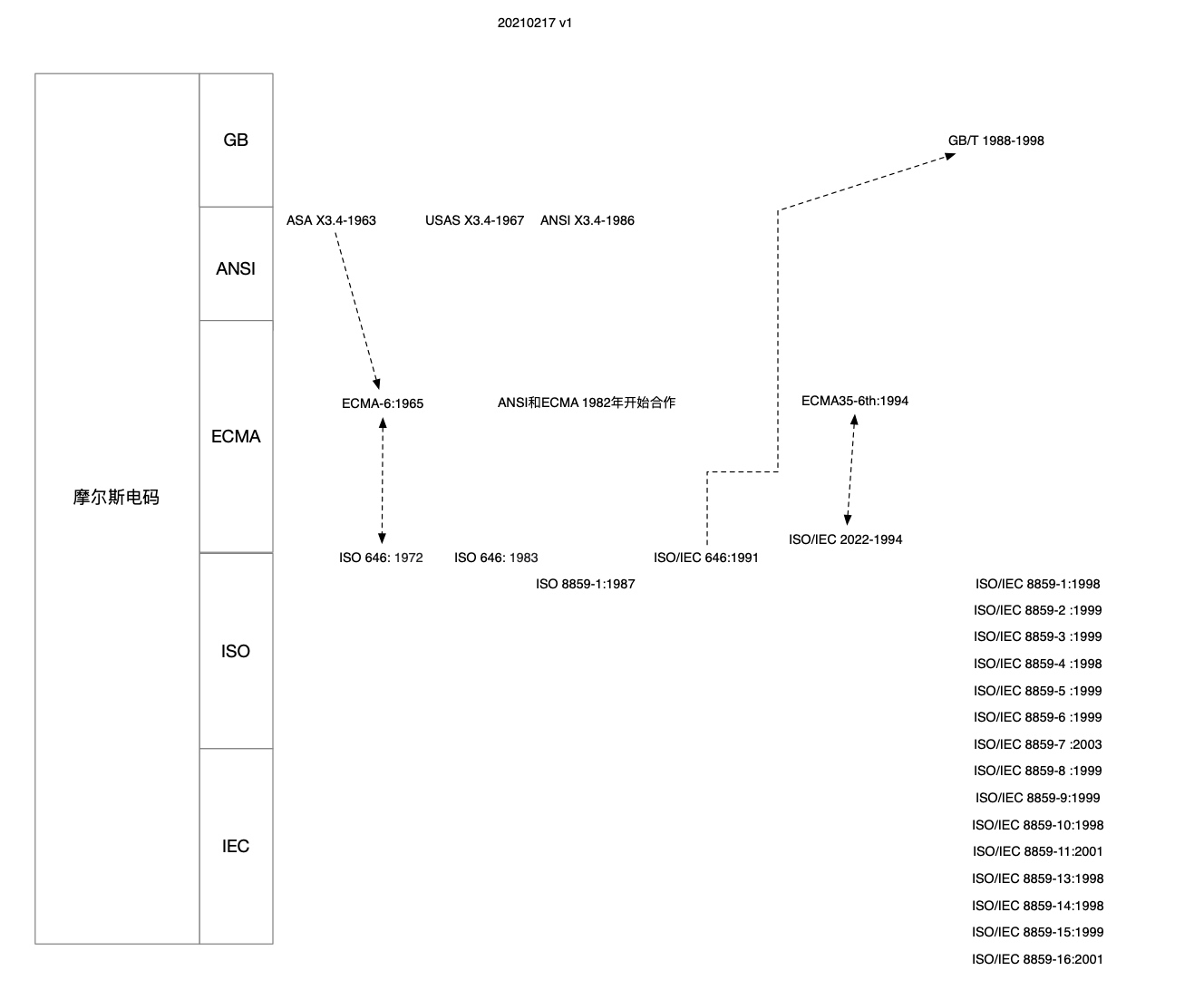
附录
术语和机构
- ISO
ISO,是国际标准化组织(InternationalOrganiza-tionforStandardization)的缩略语,是目前世界上最大、最有权威性的国际标准化专门机构。成立于1947年2月23日,总部设在瑞士日内瓦.前身是国家标准化协会国际联合会ISA和联合国标准协调委员会UNSCC.1947年ISO成立时,IEC即与ISO签订协议:作为电工部门并入ISO,但在技术和财政上仍保持其独立性。1976年ISO与IEC达成新的协议:两组织都是法律上独立的团体并自愿合作。协议分工,IEC负责电工电子领域的国际标准化工作,其他领域则由ISO负责。
按照ISO章程,其成员分为团体成员和通信成员。团体成员是指最有代表性的国家标准化机构,且每一个国家只能有一个机构代表其国家参加ISO。通讯成员是指尚未建立国家标准化机构的发展中国家(或地区)。通讯成员不参加ISO技术工作,但可了解ISO的工作进展情况。 更详细介绍:http://www.sac.gov.cn/gzfw/jgcx/gjbzh/gjbzh/201506/t20150630_190225.htm
- 字符集部分标准ISO涉及内容 字符集部分标准位于: https://www.iso.org/committee/45050/x/catalogue/p/1/u/0/w/0/d/0 stage归类上:属于90.93和60.60.
(二)IEC
IEC是国际电工委员会(InternationalElec-trotechnicalCommission)的缩略语,成立于1906年,负责有关电气工程和电子工程领域中的国际标准化工作,总部设在瑞士日内瓦。
IEC的宗旨是,促进电气、电子工程领域中标准化及有关问题的国际合作,增进国际间的相互了解。目前,IEC的工作领域已由单纯研究电气设备、电机的名词术语和功率等问题扩展到电子、电力、微电子及其应用、通讯、视听、机器人、信息技术、新型医疗器械和核仪表等电工技术的各个方面。IEC标准已涉及了世界市场中35%的产品。
(三)ITU
ITU是国际电信联盟(International Telecommunication Union)的缩略语,成立于1865年5月17日,是由法、德、俄等20个国家在巴黎会议上为了顺利实现国际电报通信而成立的国际组织。
ITU的实质性工作由三大部门承担:国际电信联盟标准化部门、国际电信联盟无线电通信部门和国际电信联盟电信发展部门。其中电信标准化部门由原来的国际电报电话咨询委员会(CCIR)和标准化工作部门合并而成,主要职责是完成国际电信联盟有关电信标准化的目标,使全世界的电信标准化。ITU目前已制定了2000多项国际标准。
先有ITU,再有IEC,最后ISO(想把所有标准都收录,曾合并IEC,后IEC单独发展)
ANSI
美国国家标准学会(ANSI-American National Standards Institute)是IEC和ISO的理事和理事局成员。
IEEE
IEEE,全称是Institute of Electrical and Electronics Engineers (美国)电气和电子工程师协会),球最大的专业学术组织,IEEE的标准制定内容包括电气与电子设备、试验方法、原器件、符号、定义以及测试方法等多个领域。
ECMA
ECMA 是“European Computer Manufactures Association”的缩写,中文称欧洲计算机制造联合会。是1961年成立的旨在建立统一的电脑操作格式标准--包括程序语言和输入输出的组织。
ECMA-262 ECMAScript (规范化 脚本(script)语言)
每个组织都有自己注册的标准,有的标准被ISO/IEC收录(ECMA-146 4mm DAT 数据插件(和一样ISO/IEC 11321))
由于cnblogs图片管理比较麻烦,所以给了cnblogs是没有图片的,github有图片.
作者:luomgf
时间:2022/02/16
转载请注明出处:https://www.cnblogs.com/luomgf/p/15904688.html
图文并茂,请访问:http://luomgf.com/16443998998895.html
参考文献
-
《Windows程序设计》第5版 (美)Charles Petzold著 方敏、张胜译,第2章 Unicode简介 页码:P20-P36 ↩
-
《C Primer Plus》第6版 B.7 参考资料VII:扩展字符支持 ,页码:P716-P720 ↩
-
《7-bit character sets发展历史》 ↩
-
ASCII维基百科介绍,2 History章 ↩
-
American Standard Code for Information Interchange ASA standard X3.4-1963.pdf ↩
-
《Linux C编程一站式学习》,宋劲杉,附录 A. 字符编码,页码:P727-P734 ↩
第三章 统计语言模型
- 作者:luomgf
- 163mail:luomgf
- 说明:转载请注明出处,系本人原创阅读分享,欢迎有兴趣的机器学习、人工智能和自然语言处理技术学习的朋友一起交流
- 地址:https://www.cnblogs.com/luomgf/p/10971773.html
第3章 统计语言模型
n元模型也就是统计语言模型,也是n-1阶马尔可夫模型,基于的是马尔可夫假设
1、用数学的方法描述语言规律
\[\begin{equation} P(S)=P(w_1,w_2,w3,\cdots,w_n) \end{equation} \]根据条件概率公式:
\[\begin{equation} =P(w_1|<s>)P(w_2|w_1)P(w_3|w_1,w_2),\cdots,P(w_i|w_1,w_2,w_3,\cdots,w_{i-1}),P(w_n|w_1,w_2,w_3,\cdots,w_{n-1})) \end{equation} \]根据马尔可夫假设: 当N=2,二元模型
\[ \approx P(w_1|<s>)P(w_2|w_1)P(w_3|w_2)P(w_i|w_{i-1})P(w_n|w_{n-1}) \]当N=3,三元模型
\[\begin{equation} =P(w_1|<s>)P(w_2|w_1)P(w_3|w_1,w_2)P(w_4|w_1,w_2,w_3)P(w_5|w_2,w_3,w_4),\cdots,P(w_i|w_{i-3},w_{i-2},w_{i-1}),P(w_n|w_{n-3},w_{n-2},w_{n-1})) \end{equation} \]N元模型
\[ =P(w_1|<s>)P(w_2|w_1)P(w_3|w_1,w_2),\cdots,P(w_i|w_{i-1-N},\cdots,w_{i-1}),P(w_n|,w_{n-1-N},\cdots,w_{n-1})) \]马尔可夫假设推导形成的常见语言模型 Unigram的马尔可夫推导
| N=1 | Unigram | 一元语言模型 |
|---|---|---|
| N=2 | Bigram | 二元语言模型 |
| N=3 | Trigram | 三元语言模型 |
| N=? | N-gram | N元gram模型 |
对于任意给定单词\(w_i\),\(P(w_i)\)当取二元模型时:
\[\begin{equation} P(w_i) = \frac{ P(w_{i-1},w_i) }{ P(w_{i-1}) } \label{eq:qmath} \end{equation} \]\( P(w_{i-1},w_i)\)是联合概率,\(P(w_{i-1})\)是边缘概率。我们要计算这两个的概率,需要用到大数定理。当有大量重复事件时,事件发生的频率接近于概率。
\[\begin{equation} f(w_{i-1},w_i)=\frac{\#(W_{i-1},w_i)}{\#} \end{equation} \] \[\begin{equation} f(w_{i-1})=\frac{\#(W_{i-1})}{\#} \end{equation} \]当统计量足够,相对频度和概率就几乎相等。(同时这个地方的假设我个人认为也是对我们的语料库提出了要求。)
\[\begin{equation} f(w_{i-1},w_i)=\frac{\#(W_{i-1},w_i)}{\#}\approx P(w_{i-1},w_i) \end{equation} \] \[\begin{equation} f(w_{i-1})=\frac{\#(W_{i-1})}{\#}\approx P(w_{i-1}) \end{equation} \] \[ \begin{equation} P(w_i|w_{i-1})=\frac{P(w_{i-1},w_i)}{P(w_{i-1})}\approx \frac{f(w_{i-1},w_i)}{f(w_{i-1})} =\frac{\frac{\#(w_{i-1},w_i)}{\#}}{\frac{\#(w_{i-1})}{\#}} =\frac{\#(w_{i-1},w_i)}{\#(w_{i-1})} \end{equation} \]###本节提到的概念 联合概率 边缘概率 条件概率 马尔可夫假设 大数据定理 语料库 相对频度
###本节人物 费里尼克 马尔可夫 李开复 罗赛塔
2、延伸阅读:统计语言模型的工程诀窍
2.1、高阶语言模型
N合适的取值是2-3
- 空间复杂度
- 计算速度
马尔可夫假设局限性和文本长程依赖性
2.2 模型的训练、零概率问题和平滑方法
2.2.1 模型的训练
使用语言模型的条件是得知道所有词的出现条件概率值,然后将他们按照预测的句子概率相乘得到句子概率。所以我们需要先计算每一个的条件概率,这些概率值我们称为模型的参数。通过对语料的统计,得到这些参数的过程称作模型的训练。
2.2.2 零概率问题
2.2.2.1 问题出现的原因
假如我们使用二元统计语言模型,根据前面的推理公式有:
\[ P(S)\approx P(w_1|<s>)P(w_2|w_1)P(w_3|w_2)P(w_i|w_{i-1})P(w_n|w_{n-1}) \] \[\begin{equation} P(w_i|w_{i-1})=\frac{P(w_{i-1},w_i)}{P(w_{i-1})}\approx \frac{f(w_{i-1},w_i)}{f(w_{i-1})} =\frac{\frac{\#(w_{i-1},w_i)}{\#}}{\frac{\#(w_{i-1})}{\#}} =\frac{\#(w_{i-1},w_i)}{\#(w_{i-1})} \end{equation} \]我们考虑以下两种情况
- 当\(\#(w_{i-1},w_i)=0\),即该联合词在语料库中一次都没有出现。则,$P(w_i|w_{i-1})=0$.
- 当\(\#(w_{i-1},w_i)=1,\#(w_{i-1})=1 \),即该联合词和前面的词在语料库中只出现一次。则,$P(w_i|w_{i-1})=1=100%$. 以上两种情况,从数学的推导上面看似是没有问题,但是我们结合现实情况考虑以下,这样的结论是否是完备和太过于绝对。即当该词在语料库中一次都没有我们就说这个不合理,当两个都出现1次就一定会出现,显然语料库是有可能不完整和充分的。因此这样的结论和概率是不合适的,需要我们解决该问题。
- 运用更为通俗的学生例子加以解释
2.2.2.2.2 0概率问题解决办法
最直接的办法:增加数据量,因为我们都知道根据大数定理,当量一定程度后其频率都比较接近概率,因此我们对这些出现一次的再增加就可以使其逼近真实概率。 但是现实生活中大的数据量只是一个相对的概念,因此最后都会面临一个0概率或者100%的问题。
- 古德图灵估计原理: 对于没有看见的事件,我们不能认为他发生的概率是0,因此我们从概率总理中,分配一个很小的比例给这些没有看见的事件。这样以来看见的那些时间的概率总和就要小于1了,因此,需要将所有看见的事件概率调小一点。至于小多少。要根据“越是不可信的统计折扣越多的”的方法进行。
- 古德-图灵估计语料估计过程 假定在语料库中出现r次的词有\(N_r\)个,特别地,未出现的词数量\(N_0\)个,语料库的大小为N。则有:
这个的意思就是,比如出现100次的有“我”“你”“他”三个词,则N=3*100=300 对于出现r次的词在整个语料库中的相对频度则是:
\[\begin{equation} 出现r次的词在整个语料库中的相对频度=rN_r/N \end{equation} \]现在我们看是如何运用的 如果r次数比较小--》统计不可考---〉需要调整---》这个地方我们调整次数即可---〉用\(d_r\)代替r--->其满足如下古德图灵公式:
\[ d_r=(r+1)N_{r+1}/N_r=(r+1)\frac{N_{r+1}}{N_r} \]同时以下等式也是成立的: \(\sum_rd_r\cdot N_r=N\)
- zipf定律 背景知识:根据观察一般语料库中,出现一次的词的数量比出现两次的多,出现两次的比出现三次的多。即出现次数越多的词,数量越少,出现次数越少的词数量越多。这个很好理解,常用词出现的次数很多,但是数量很少,其他不常用词出现次数少,但是量大,因为中文或者词语有几千个字,常用的不多,所以出现次数越多的单身数量却不多,不常用字生僻字还是占据了很大一部分,所以数量多,但是用的次数少。 理解记忆小技巧:这就好像,r类似考试的100道题,能够做100分的活着高分的能人数很少,但是做个普通分数或者低分的人数量很多,有些类似或者可以这么记。 即,只有极少数的词被经常使用,而绝大多数词很少被使用.
- 古德图灵估计-2元模型
- 古德图灵估计-3元模型
语料库
- 训练语料和模型应用领域需要相关,最好一致,比如不要用中华字典语料取训练网络流行语应用
- 语料有适当噪声没有关系,因为他跟贴近实际。
- 训练数据理论上越多越好
- 由于实际过程中大部分语料不足,不要片面追求高阶模型,因为高阶模型需要训练的参数多,需要的数据更多。
- 对语料数据,处理中,对于一些有规律、模式的噪声应该加以清除过滤。
本节概念
zipf定律 卡茨退避法 不平滑模型,即条件概率大部分为0的模型。 概率估计,统计语言模型的训练好坏的艺术就是在统计样本不足的情况下如何更好的概率估计。 古德图灵估计(Good-Turing Estimate)
疑问
中文语料库是否具备zipf定律,如何运用中文语料库和英文语料库进行重现。
###本节数学符号
- \(\#\) 语料库大小
- \(r\) 某个词在语料库中出现的次数为r
###参考链接
- http://www.52nlp.cn/%E4%B8%AD%E8%8B%B1%E6%96%87%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E8%AF%AD%E6%96%99%E4%B8%8A%E7%9A%84word2vec%E5%AE%9E%E9%AA%8C 吴恩达马尔可夫 http://open.163.com/movie/2008/1/2/N/M6SGF6VB4_M6SGKSC2N.html 吴恩达序列模型-nlp https://mooc.study.163.com/learn/2001280005?tid=2001391038#/learn/content
- 作者:luomgf
- 163mail:luomgf
- 说明:转载请注明出处,系本人原创阅读分享,欢迎有兴趣的机器学习、人工智能和自然语言处理技术学习的朋友一起交流
- 地址:https://www.cnblogs.com/luomgf/p/10971773.html

Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.